Paper link | Note link | Code link | AAAI 2024
整體想法
本研究提出了一個基準來評估大型語言模型在檢索增強生成(Retrieval-Augmented Generation, RAG)中的性能。
摘要
現有研究缺乏一個評估檢索增強生成(RAG)影響的基準。
本研究提出了一個系統化的分析,基於RAG所需的四項基本能力來評估各種大型語言模型的性能:
- 噪聲魯棒性(Noise Robustness)
- 負面拒絕(Negative Rejection)
- 資訊整合(Information Integration)
- 反事實魯棒性(Counterfactual Robustness)

背景
檢索增強生成(RAG)被認為是解決諸如幻覺、過時知識和缺乏領域專業知識等問題的有前景的解決方案。
然而,RAG也帶來了潛在的缺點。通過RAG檢索的資訊可能包括虛假新聞,這可能會導致大型語言模型生成不可靠的輸出。
因此,對大型語言模型進行全面的評估,以衡量其有效利用檢索資訊的能力是非常重要的。
方法
這篇論文對大型語言模型中的檢索增強生成(RAG)進行了評估,即檢索增強生成基準(Retrieval-Augmented Generation Benchmark, RGB)。
該評估支持英語和中文。
此評估使用四個測試平台來評估大型語言模型的以下基本能力,以解決RAG中的常見挑戰:
-
噪聲魯棒性(Noise Robustness):
大型語言模型能否從嘈雜的文檔中提取有用的資訊?
-
負面拒絕(Negative Rejection):
大型語言模型能否在檢索的文檔中缺乏所需知識時拒絕回答問題?
-
資訊整合(Information Integration):
大型語言模型能否回答需要整合多個文檔中的資訊的複雜問題?
-
反事實魯棒性(Counterfactual Robustness):
大型語言模型能否在收到潛在風險警告後識別檢索文檔中已知事實錯誤的風險?

關於RGB數據生成:
-
模型(如ChatGPT)用於從新聞文章中提取(事件、問題、答案)三元組。
-
搜索引擎(如Google API)然後用於檢索相關的網頁。
- 最後,使用密集檢索模型對這些網頁的內容進行重新排名。
以下是他們實驗中使用的指令:

實驗
大型語言模型
- ChatGPT
- ChatGLM-6B
- ChatGLM2-6B
- Vicuna-7b-v1.3
- Qwen-7B-Chat
- BELLE-7B-2M
評估指標
-
準確率(Accuracy):
用於衡量噪聲魯棒性和資訊整合。
-
拒絕率(Rejection Rate):
用於衡量負面拒絕。
-
錯誤檢測率(Error Detection Rate):
衡量模型是否能檢測到文檔中的事實錯誤,用於反事實魯棒性。
-
錯誤修正率(Error Correction Rate):
衡量模型在識別錯誤後是否能提供正確答案,用於反事實魯棒性。
噪聲魯棒性

可以看到,噪聲率的增加對RAG中的LLMs構成挑戰。
負面拒絕

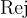 表示拒絕率(%),而
表示拒絕率(%),而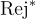 表示ChatGPT評估的拒絕率。
表示ChatGPT評估的拒絕率。
資訊整合

與“噪聲魯棒性”中的表格比較,可以觀察到模型在資訊整合能力方面較弱,這反過來影響了其噪聲魯棒性。
反事實魯棒性

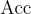 是沒有外部文檔的LLMs的準確率(%)。
是沒有外部文檔的LLMs的準確率(%)。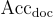 是帶有反事實文檔的LLMs的準確率(%)。
是帶有反事實文檔的LLMs的準確率(%)。
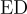 和
和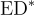 分別是通過精確匹配和ChatGPT評估的錯誤檢測率。
分別是通過精確匹配和ChatGPT評估的錯誤檢測率。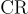 是錯誤修正率。
是錯誤修正率。


 iThome鐵人賽
iThome鐵人賽